ML на клиенте: Часть 2. Продвинутое распознавание белочек.
Нужно больше цифровых белочек!
В первой части мы с вами отлично поработали: перестали бояться математики, научились узнавать белочек и заглянули внутрь классифицирующей нейросети. Теперь попробуем улучшить нашу предыдущую модель и сделать так, чтобы она узнавала белочек еще лучше. Мы снова будем использовать tensorflowjs и tensorflow. Поехали :)
Что можно улучшить?
В прошлом разделе мы взяли уже готовую модель, обученную на ImageNet. Она умеет распознавать множество классов, но это немного не то, что нам было нужно. Мы хотим отличать белочек от прочей живности. При этом распознавать шторки для ванной или пожарные гидранты нам не обязательно.
Сначала сформулируем задачу — мы хотим распознавать белочек, котиков, собачек, лошадок... ну вы поняли:)
const classes = [
'dog',
'horse',
'elephant',
'butterfly',
'chicken',
'cat',
'cow',
'sheep',
'spider',
'squirrel',
]
Кстати, о постановке задач
Я искренне считаю, что перед тем, как начинать пилить любую фичу, надо потратить некоторое время, чтобы понять, что именно от нас требуется. И только после этого начинать собственно пилить. Это сэкономит время, ресурсы и иногда даже нервы.
Заглянем внутрь текущей модели:


Тут все хорошо, кроме последнего слоя. Все, что нам нужно сделать, это оторвать у нашей сети хвост и приделать новый. Как я уже упоминала, сеть в tensorflow — это граф, и мы можем перестраивать его как нам нравится. Эту технику можно использовать как на клиенте, так и на сервере. API, правда, будет немного отличаться.
Вот так мы соединяем слои в tensorflowjs:
const inputs = oldModel.layers[0].input
const output = oldModel.layers[3].output
const newLayer = // как-то определили новый слой
const outputs = newLayer.apply(output)
newModel = tf.model({ inputs, outputs })
A вот как если используем питонячью реализацию:
inputs = old_model.input
out = old_model(inputs)
new_layer = # как-то определили слой
outputs = new_layer(out)
new_model = keras.Model(inputs=inputs, outputs = outputs)
Сейчас нам нужно заменить старый слой Dense(1000) на новый Dense(10), где 10 - это количество элементов в classes.
Дальше нам нужно потренировать новую модель на котиках, лошадках, белочках и остальных зверушках из classes.
Раздобыть подходящий dataset для тренировки можно, например, на kaggle.
Еще одна хорошая новость – нам не нужно обучать все слои новой сети. Достаточно просто потренировать наш новый хвост.
Для этого нужно "заморозить" все предыдущие слои. То, что мы сейчас проделываем, используется очень часто и называется transfer learning. Есть куча гайдов о том, как это правильно готовить. Вот, например, от tensorflow
Не обязательно тренировать только один слой
Мы можем потренировать и остальные слои, если нам захочется. Это потенциально может добавить нашей модельке точности. Для этого нужно "разморозить" все нужные слои. Обычно размораживают несколько последних.
Примерно так будет выглядеть ваш финальный код на питончике:
headless_model.trainable = False
outputs = headless_model(headless_model.input, training=False)
dense_out = layers.Dense(10, activation="softmax")(x)
classifier = keras.Model(inputs=headless_model.input, outputs = dense_out)
Тренировка не займет много времени. На моем маке (с M1 :) ) мне понадобилось примерно две минуты, чтобы дообучить новую модель.
Теперь нужно сконвертировать обученное и скормить это браузерному tensorflow. Если мы используем tensorflow для обучения и если мы не пишем никакого экзотического кода, с конвертацией проблем не возникнет.
Так у меня весь код экзотический!111
У меня тоже, хе-хе. Я планирую чуть более подробно рассказать о конвертации в следующих частях. Сейчас предлагаю использовать вот такое правило: используем только операции из этого списка По возможности, никаких кастомных слоев и никаких кастомных моделей.
Сохраняем модель в формате h5, потом конвертируем при помощи tensofrlowjs_converter
!tensorflowjs_converter \
--input_format=keras \
--output_format=tfjs_layers_model \
{model_in_path} \
{model_out_path}
Как загрузить модель, мы уже знаем:
await tf.loadLayersModel(modelUrl)
Давайте загрузим сразу обе модели: старую с последним слоем на 1000 классов и новую. И сравним, что получилось:
oldModel.summary()
newModel.summary()

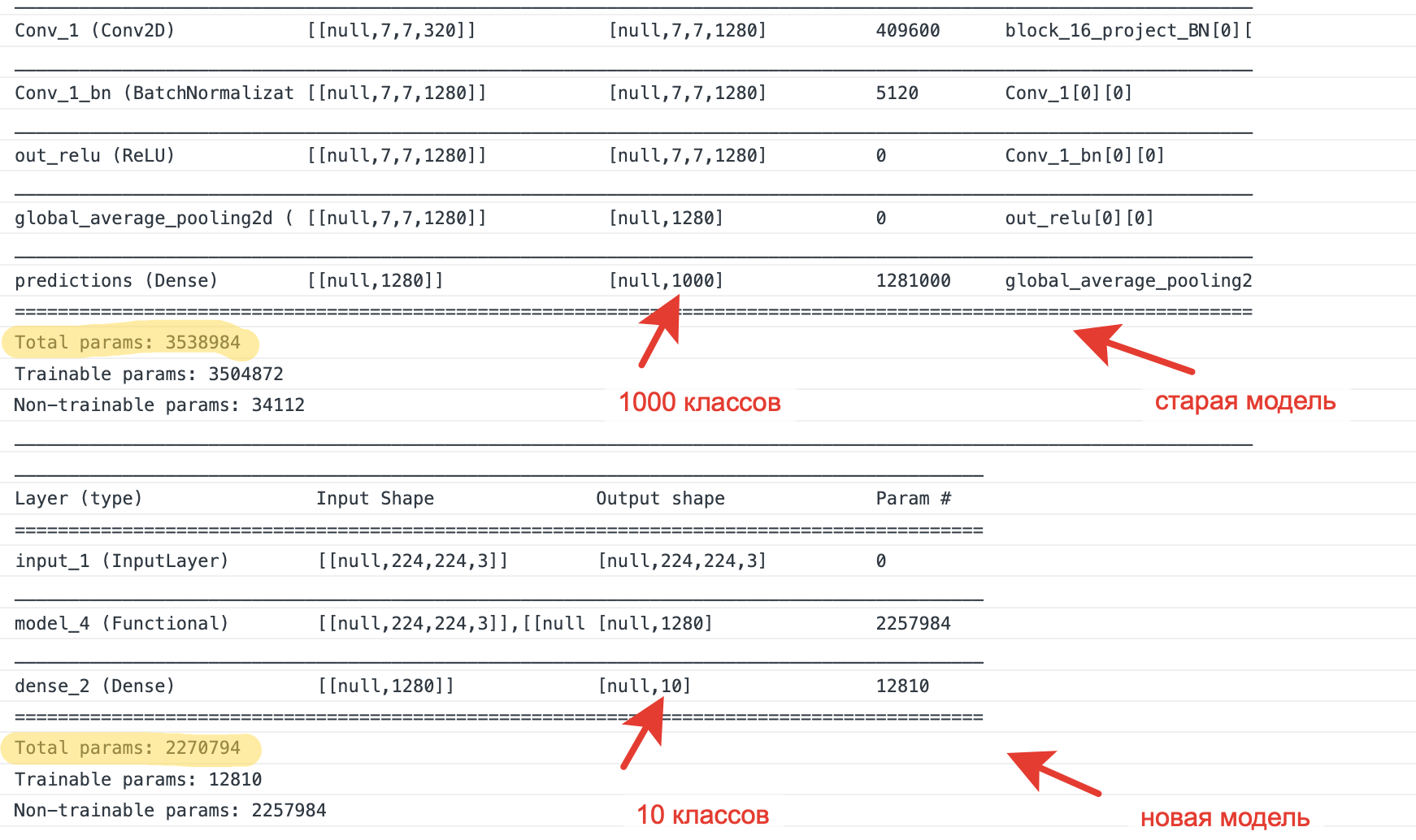
Вторая модель выглядит странно. Куда подевались все наши слои? Из-за того, что мы немножко перетрясли граф, весь MobileNet теперь запрятан внутрь model_4.
У второй модели меньше Trainable parameters. Разберемся почему.
Обратите внимание на последний слой - теперь там 10 классов. Ровно то, что мы хотели.
Тип этого слоя – Dense (переводится вроде бы как полносвязный слой) – все элементы такого слоя соединены со всеми элементами предыдущего.
Как видно из картинки, на предыдущем слое у нас prevOutput = 1280 параметров. Нам надо соединить их с lastOutput = 1000 параметрами на новом слое.
Плюс нам надо еще добавить вектор bias, чья размерность совпадает с размерностью последнего слоя lastOutput.
Проверим, что это действительно так:
const logModelInfo = (model: LayersModel) => {
model.summary()
const totalParams = model.countParams()
const lastLayer = model.layers.slice(-1)[0]
const prevLayer = model.layers.slice(-2)[0]
const lastOutput = lastLayer.outputShape[1]
const prevOutput = prevLayer.outputShape[1]
console.log('totalParams = ', totalParams)
console.log(
`on the last layer = ${lastOutput} * ${prevOutput} + ${lastOutput}`
)
}
В результате у нас стало на (1280 * 1000) + 1000 - (1280 * 10) - 10 = 2560 параметров меньше. И наша модель похудела на 5.2Mb
C точностью теперь все тоже хорошо :)
Было:
Стало:
Итеративные оптимизации наше все
У нас получилось разобраться в transfer learning и уменьшить размер нашей модели. Но это только первые шаги :)
Мы используем не самый эффективный формат layersModel и пока не понимаем, как все работает под капотом.
В следующих постах нас ждут новые оптимизации и генераторы белочек :)