Потоки основные и не очень 🤔
"Во сколько потоков может выполняться программа на JavaScript" – такое любят спрашивать на собеседованиях. Правильный ответ - 🤷♀️. А вот "один" это менее правильный ответ. Если встретите такой вопрос, обязательно уточните где и чем выполняется упомянутая программа.
Откуда вообще взялся этот "одни" поток? Когда говорят о производительности, часто вспоминают однопоточную модель выполнения JavaScript и переживают как бы не заблокировать основной поток (main thread). В этой статье мы познакомимся с основным потоком поближе.
Откуда начинаются потоки?
CPU (так же известный как процессор:) выполняет инструкции. В зависимости от устройства процессора, порядок и количество одновременно выполняемых инструкций может быть разным. На эту тему можно беконечно читать википедию, начать можно например отсюда.
SIMD
Процессоры также имеют расширения, позволяющие обрабатывать несколько значений одной инструкцией. Это называется SIMD (Single Instruction Multiple Data). Ваш процессор наверняка умеет это делать. Расширение предоставляет дополнительный регистр куда можно записать сразу несколько значений и специальные инструкции чтобы работать с этим регистром.
Программкам очень хочется выполнять свой код, для этого им нужен процессор. Программок много, ядер процессора не много. Операционная система дает немножко поработать каждой программе (термин программа кривой, мы позже определим что это значит) создавая иллюзию одновременной работы нескольких программ. Для этого OS устанавливает таймер, на некоторое количество времени, называемое кватном. Код программы загружается на процессор и процессор начинает последовательно выполнять инструкции этой программы. Через некоторое время срабатывает таймер и операционная система генерирует специальную инструкцию процессора – прерывание. Обработчик прерывания сохраняет контекст (набор регистров) текущей программы, загружает контекст другой программы и снова устанавливает таймер. Поэтому одновременное исполнение многих программ это всего лишь иллюзия. На самом деле процессор просто быстро переключается между программами. Если программе понадобилось подождать (IO) то также генерируется прерывание. Чтобы понять какому процессору нужно дать поработать в OS используется планировщик.
Что значит одновременно?
Есть два термина: Concurrency – несколько задач могут перекрываться по времени. Это не значит что они всегда выполняются одновременно. Parallelism – честное параллельное выполнение. Например на разных ядрах процессора.
Поправим терминологию
Ваша программа может создать один или несколько процессов. Процессы выполняются независимо друг от друга и имеют уникальные айдишники (pid). У каждого процесса есть свое адресное пространство и состояние. Состояние процесса это то, что сейчас хранится в регистрах процессора. Кроме этого, операционная система может выдать процессу каких-нибудь объектов, например файлов и сокетов. Также операционная система будет следить, чтобы адресные пространства разных процессов не пересекались.
Что насчет браузера?
Первое что вы нагуглите по запросу "Chomium Architecture" – Хром это multi-process application. Каждая вкладочка это свой собственный процесс.
Код внутри процесса может выполняться местами параллельно - в несколько потоков. Системные потоки делят адресное пространство процесса. В одном процессе всегда выполняется хотя бы один поток. Каждый поток внутри процесса имеет свой стек. А вот кучу процессы шарят. Выполнять ваш код в несколько потоков может быть полезно. Параллельное выполнение часто быстрее однопоточного.
Что за стек и куча?
Посмотрите вот эту статью в Доке. В ней я рассказываю как устроена память. Модель, описанная в статье отличается от той, которая используется в вашей OS. Но для общего понимания ее достаточно.
Процессы связаны и образуют иерархию. Одни процессы могут создавать другие процессы. Потоки так не умеют.
А как на нее посмотреть?
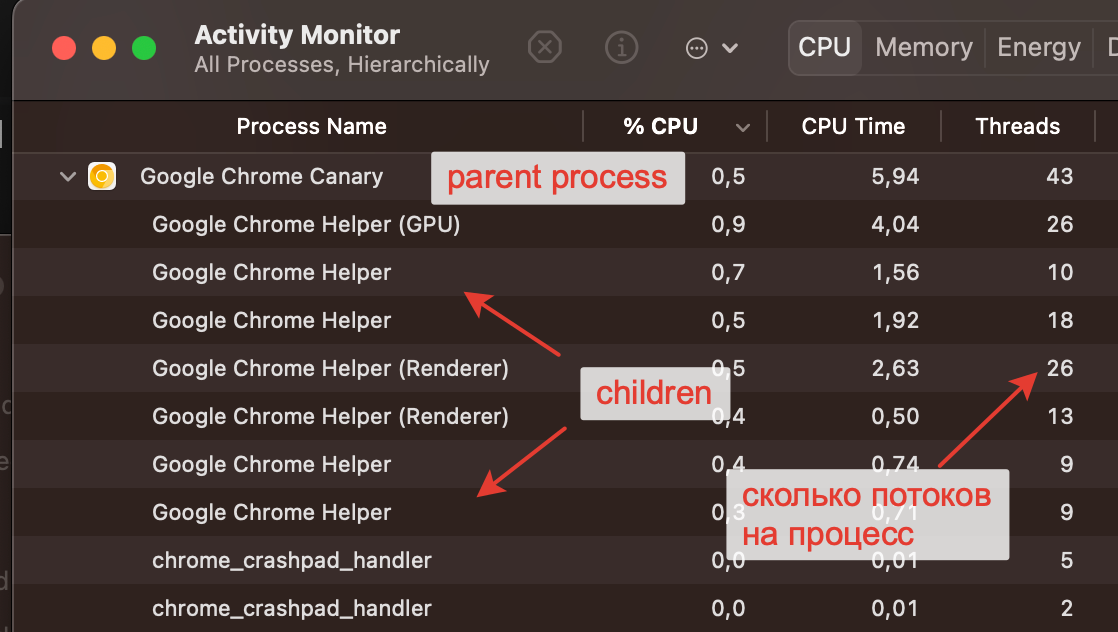
Найти предка процесса можно посмотрев на его атрибут ppid. Это сработает на
macOS и Linux. В Linux вы также можете выполнить команду pstree. В macOS
можно заглянуть в activity monitor и включить там tree view.
Процессы могут общаться между собой при помощи системы сигналов или какого-то пошаренного ресурса. Например вы можете писать код в один файлик из разных IDE :)
Операционные системы содержат специальные API которые помогают вам создавать потоки. Иногда эти потоки называют физическими потоками. Когда вы пишете программу на каком-нибудь языке, при ее выполнении нужно выполнить дополнительный код, который написали не вы – рантайм. Языковые рантаймы могут либо мапить свои потоки на потоки операционной системы (1:1), либо создавать свои собственные потоки (green threads). Эти потоки могут выполняться в нескольких потоках операционной системы (M потоков рантайма: N потоков OS).
Что же планирует планировщик
Разумеется планировщики разных операционных систем работают по-разному. Но в целом они скорее планируют потоки чем процессы.
Потоки в Браузере
Инфа для этого раздела в основном утащена отсюда
JavaScript это язык на котором пишут програмки. Выполняет эти программки какая-то среда. В Chome и NodeJS движком JS является V8, а рендерингом занимается Blink. Мы будем говорить об основном потоке именно в контексте V8 и Chromium и Blink.
Устроено все так: В браузере есть несколько процессов, в каждом процессе несколько потоков.
- Main thread – основной поток
- IO thread (это не тот IO о котором вы подумали)
- Compositor thread
- Пул потоков для выполнения всякого-разного (task pool)
- GPU thread для рисования конента активного таба и UI браузера на экране
Подготовка отрисовки происходит в собственном в render процессе. Внутри этого процесса есть один основной поток (main thread), пул вспомогательных потоков и поток отвечающий за композицию слоев.
Многие оптимизации, которые предоставляют Blink завязаны на эту поточную модель (main thread всегда один). Это не значит что вы не можете создавать дополнительные потоки.
WebWorkers и ServiceWorkers живут с своих собственных потоках. Blink может использовать потоки из пула чтобы задекодить картинку или процессить звук.
Основной поток как и другие потоки в рамках rendering-процесса 1:1 мапится на физический поток операционной системы.
То же самое валидно для WebWorkers и ServiceWorkers.
В каком процессе живут WebWorkers и ServiceWorkers?
WebWorker работает внутри rendering процесса вашей вкладки. ServiceWorker живет в отдельном процессе.

Что именно будет выполняться в основном потоке определяется пралировщиками, которые разбирают несколько очередей. В этиx очередях собираются различные задачи. На то как устроены задачи можно посмотреть, например тут
А что об этом говорится в спецификации?
Почти ничего. Единственное место про потоки я нашла вот тут
Все очень безопасно и поэтому сложно
Браузер должен гарантировать что злобный код с одной странички не начнет портить другие и не повлияет на производительность своих соседей. Посадить сайт в песочницу не только сложно но и затратно по ресурсам. Прибавьте к этому существование iframe и браузерных расширений. Поэтому иногда rendering процесс может переиспользоваться для нескольких вкладок одного и того же сайта.
Кроме процессов отвечающих за рендеринг вкладок, есть еще два важных процесса: Browser process - отвечает за рендеринг UI браузера GPU process - отвечает за рисования всего что есть в браузере в том числе и вкладок.
Rendering процесс
Материалы этого раздела это микс из замечательного видео Life of a pixel by Steve Kobes (Видео достаточно старое, но оно отлично показывает куда смотреть в исходниках чтобы разобраться как все работает. Кроме того основные идеи не изменились) И выдержек из блога RenderingNG
Чем же занимается rendering процесс? – Практически всем :)
Давайте посмотрим на типичный rendering pipeline. Итак у нас есть кусочек текста HTML. Его нужно:
Распарсить Вырастить из него дерево (DOM)
Настает очередь CSS. (На самом деле это можно делать и параллельно) Из текста CSS нужно вытащить правила, разобрать их на селекторы и свойства. Теперь нам нужно пройтись по DOM и понять какой сет правил к нему относится. В результате получается настоящий лес из property tree.
После этого нужно разместить все элементики на страничке. Это называется layout.
В процессе размещения элементов на странице нужно вырастить очередное дерево (fragment tree).
Не путайте это дерево с DOM.
При построении fragment tree часть нод может просто исчезнуть. Например если у ноды есть свойство display: none.
В процессе построения и перестроения алгоритм layout не запускается с самого начала.
Результаты предыдущего выполнения алгоритма кешируются.
После построения "скелета" страницы, нужно добавить туда красивые пиксели. Если что-то анимируется или страничка перерисовывается, то перед рисованием браузер заглядывает в кеши и определяет какие структуры и текстуры уже не валидны. Этот шаг называется pre-paint.
Если пользователь что-то скролит, нужно обновить отступы для скрола. Этап scroll
Дальше происходит paint при этом строится список команд, которыми будет нарисован контент на страничке.
На этапе commit готовые для рисования структуры данных уезжают в другой поток - compositor.
Compositor поделит все на отдельные слои - Layerize. Каждый слой можно растеризовывать отдельно. Чтобы это работало эффективно, нужно выделять слои таким образом чтобы их изменения не зависили друг от друга. Далее происходит Raster и decode - нам нужно превратить картиночки и структуры с передыдущих шагов в набор команд для областей (клеток). Нарезать на клетки полезно чтобы не перерисовывать весь котнет странички.
Activate + Aggregate - собрать это все вместе в набор команд для GPU. Draw - отправить команды в GPU которая нарисует вам пиксели на экране.
Ура, все нарисовалось! Теперь можно менять то получилось при помощи JavaScript. Источниками обновлений может быть не только JS но и всяческие анимации и действия пользователей.
Чтобы не прогонять весь pipeline, используются магические функции которые для каждого элемента на нужном этапе опредляют нужно ли его пересчитывать или перерисовывать. Шаги rendering pipeline и JavaScript могут выполняться параллельно. Например анимации могут проиходить в Сomposite потоке, в то время как основном поток занят вычислениями.
Давайте посмотрим как это работает
Сначала напишем ужасную функцию поиска чисел делящихся на 7
Этой функцией мы будем сурово блокировать основной поток. Наблюдать результаты блокировки можно, визуально. Но лучше заглянем в Chrome DevTools на вкладку Performance. Попробуйте посмотреть и предсказать что будет для каждого из типа анимаций когда мы заблокируем основной поток. После этого попробуйте поскролить страницу при блоке. Как думаете, почему она все-таки скролится?
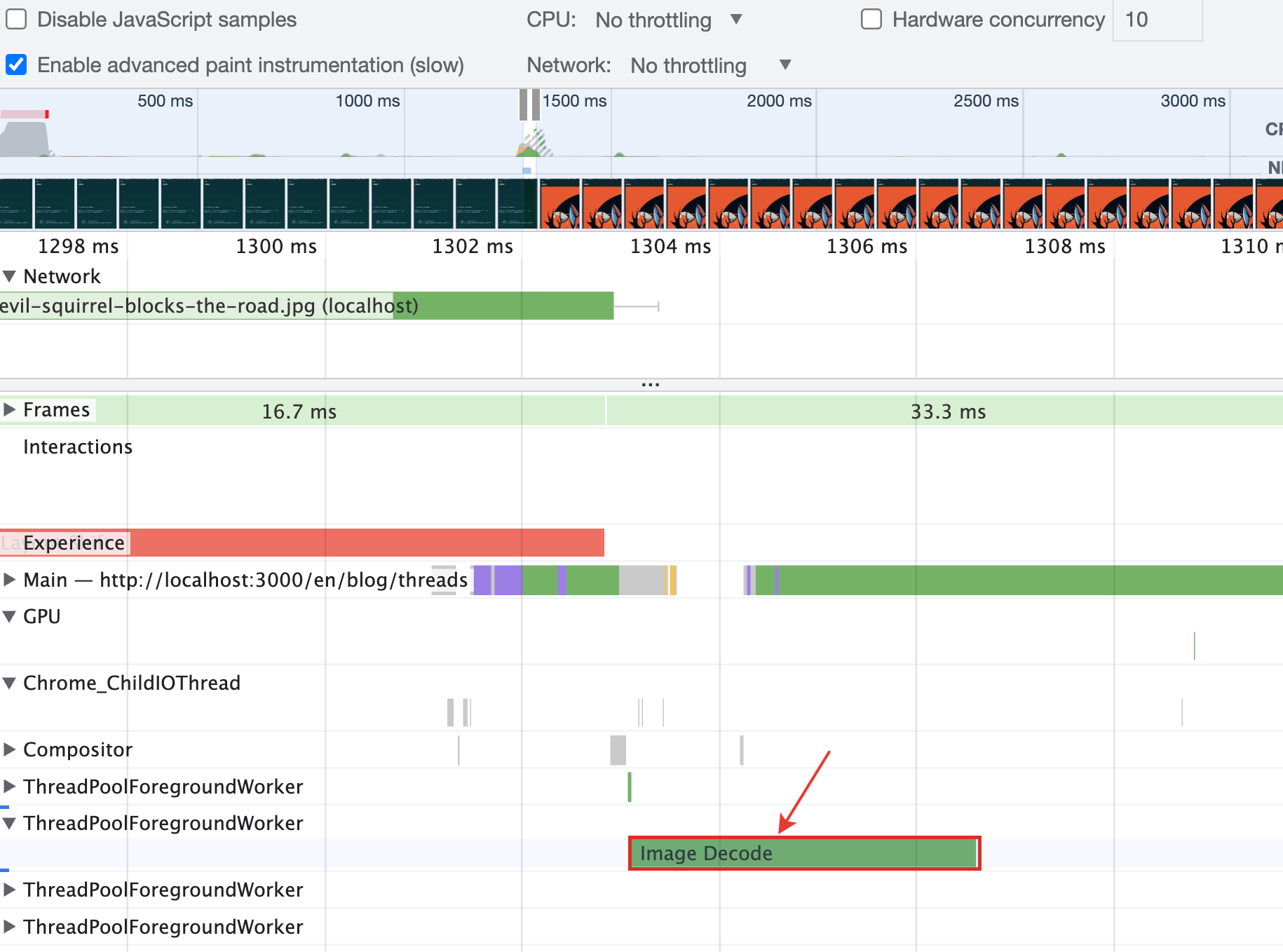
Второй пример показывает как используются дополнительные потоки. Попробуем загрузить несколько картинок c включенным профилированием. Обратите внимание в каком потоке происходит декодинг изображений.
Обратите внимание на ThreadPoolForegroundWorker на вкладке Performance.
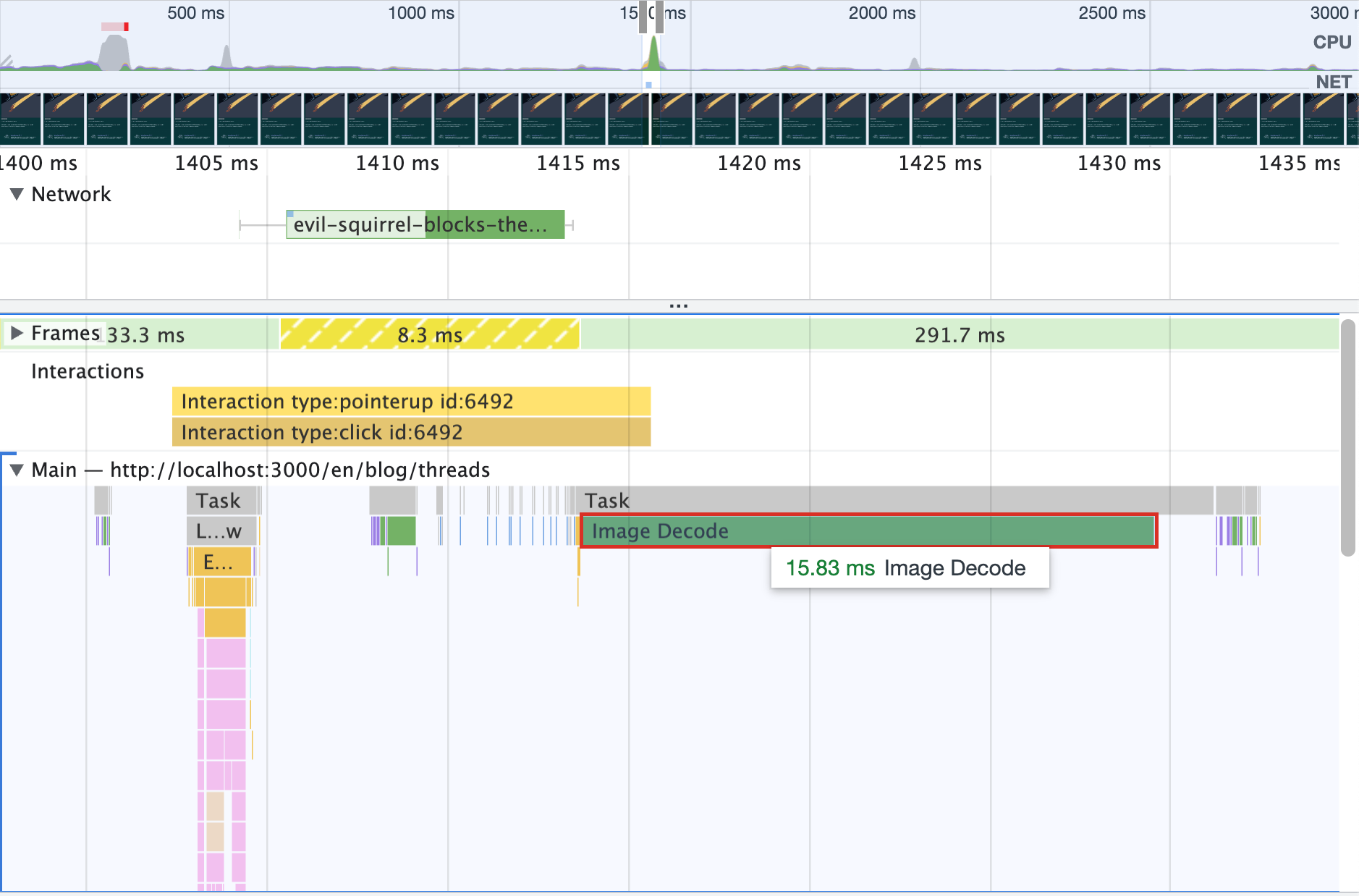
Теперь посмотрим что происходите когда браузер рисует картиночки.

Попробуйте нажать кнопку "draw on canvas" с включенным профайлером. Декодинг изображения переместился в основной поток.

Окей, а что насчет нашего любимого WebAssembly и JS? В моей статье про блюр белочек как раз есть подходящий пример.
При попытке заблюрить белочку при помощи Wasm основной поток будет заблокирован.


Если присмотреться к тому как происходит компиляция Wasm и JS, то вы можете заметить что далеко не все выполняется в основном потоке. Напомню, что компиляция у нас Just-in-time. Т.е компилируем и выполняем одновременно.


В то время как V8 (JavaScript движок в Chromium) компилирует код в основном потоке, другая часть движка занимается его параллельной оптимизацией.
Но хочется же параллельно!
Да пожалуйста. У нас есть прекрасный механизм WebWorkers
Каждый новый Worker создает новый поток (системый поток), закидывает туда экземпляр движка и заботливо выполняет ваш код.
Поток Worker создается в rendering-процессе вашей вкладки, однако он никак не может работать с DOM и не имеет доступа к структурам
памяти других потоков. Именно это делает использование WebWorkers безопасным но и достаточно медленным.
Что же делать если вы хотите передать данных вашему Worker-у на обработку? Вы можете использовать механизм postMessage.
Давайте потренируемся!
Код последней демки очень-очень простой.
// main thread
const array = new Float32Array(1000 ** 100000).fill(Math.random())
const worker = new Worker(new URL('./workerScript.ts', import.meta.url))
worker.onmessage = e => {
if (e.data === 'ready') {
console.log('worker is ready')
worker.postMessage(array)
console.log(array)
// transferable!
worker.postMessage(array, [array.buffer])
console.log(array)
} else {
setSum(e.data)
}
}
// worker thread
postMessage('ready')
onmessage = function (event) {
const data = event.data
const result = data.reduce((acc: number, item: number) => acc + item, 0)
postMessage(result)
}
export {}
Это отлично работает. Расчет суммы в воркере не блокирует основной поток.
Давайте посмотрим что происходит в DevTools:


Пре передаче значения между потоками объект нужно сериализовать и десерилизовать. В Chrome это делается при помощи structured clone и это не очень быстро.
Мы отправляем массив на воркер два раза. Во второй раз мы используем transferable опцию. Вывод в консоли будет следующим:


Если мы передаем объект через Worker через опцию transferable, данные обекта исчезнут в основном потоке.
Однако самый эффективный способ передачи данных между потоками это использование пошареной памяти.
Плохие новости – вы не можете его использовать :( По-умолчанию использование SharedArray buffer запрещено из-за узявимости к Spectre.
Однако вы можете включить SharedArrayBuffer, для cross-origin-isolated страниц. Для этого вам понадобится добавить в ответ с контентом вашей страницей два дополнительных заголовка:
Cross-Origin-Embedder-Policy: require-corp
Cross-Origin-Opener-Policy: same-origin
После этого вы не сможете использовать SharedArrayBuffer, но не сможете грузить Cross-Origin контент.
Точнее сможете, но не весь
Вам понадобится магия заголовков. Подробнее об этом можно прочитать вот в этом гайде
Grabage collector
Еще одна задача, выполняемая в основном потоке - сборка мусора. В Chrome мусор собирается stop-the-world сборщиком мусора, это значит что сборка мусора блокирует основной поток. Однако мусор собирается по частям и сборка разделяется между основном потоком и несколькими вспомогательными. Если вы резко увеличите объев данных хранящихся в куче, в основной поток придет сборщик мусора (major GC), что может вызвать достаточно долгую блокировку.
Так значит можно надолго блокировать основной поток?
Нельзя :) Но теперь вы знаете что даже заблокировав основной поток вы заблокируете не все (вспомните летающие кружочки из примеров выше). Я не одобряю преждевременных оптимизаций и предлагаю не бояться писать блокирующий код. Напишите и измерьте реальный эффект (не забудьте только установить нужный x4 slowdown в DevTools). Если в процессе измерений вы обнаружите проблемы в производительностью – проанализируйте ваш алгоритм. Наверняка его можно ускорить в 100500 раз. И вот если ускорить не получается – берите пример с браузера! Разбейте свой код на последовательность задач и скармливайте их основному потоку понемножку. Если очень хочется, можно даже реализовать свой собственный планировщик задач. А дальше вы можете взять пример с браузера еще раз и раскидывать эти задачи по разным потокам. После этого можете считать что ачивка "потоки мне покорились" получена.